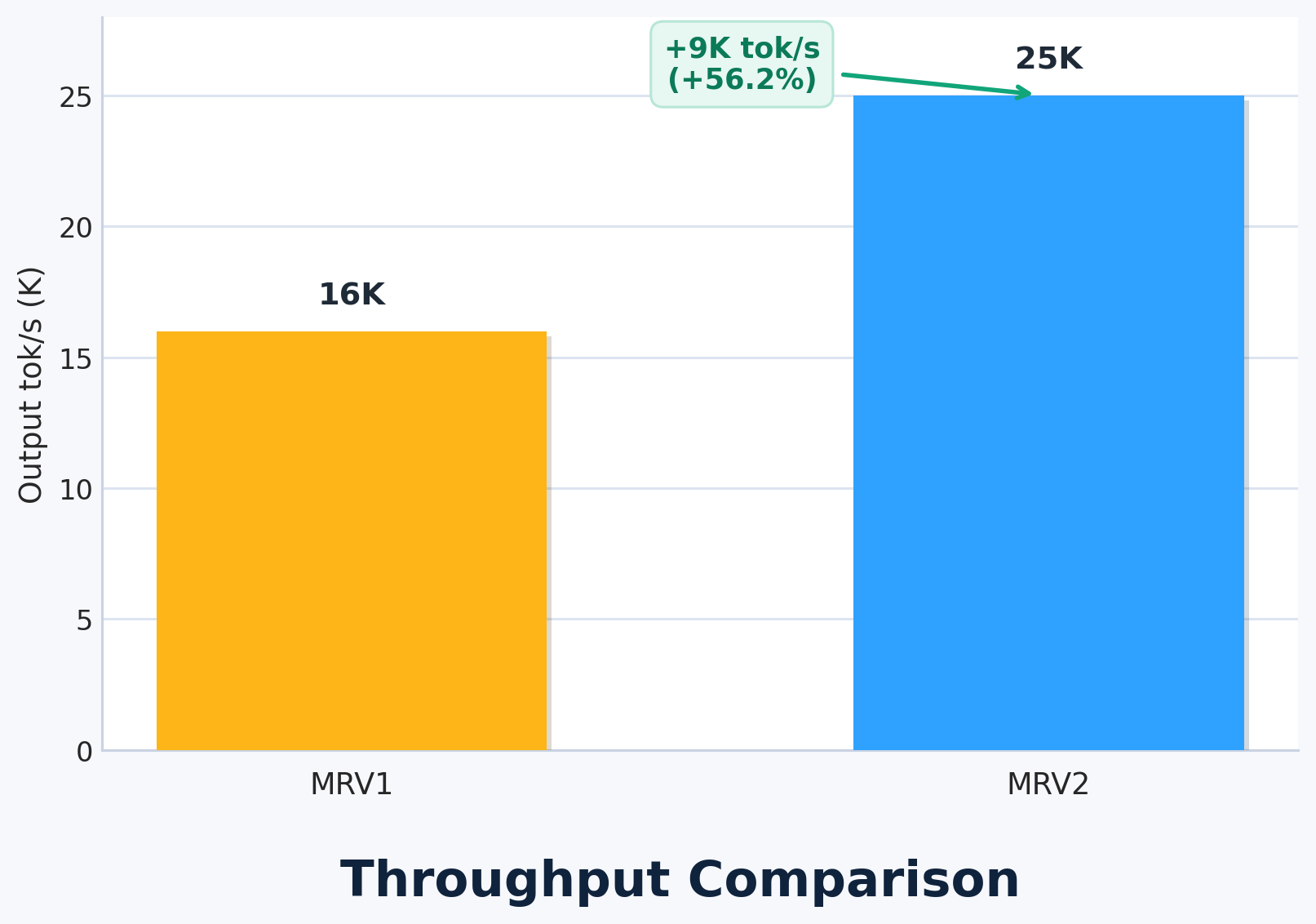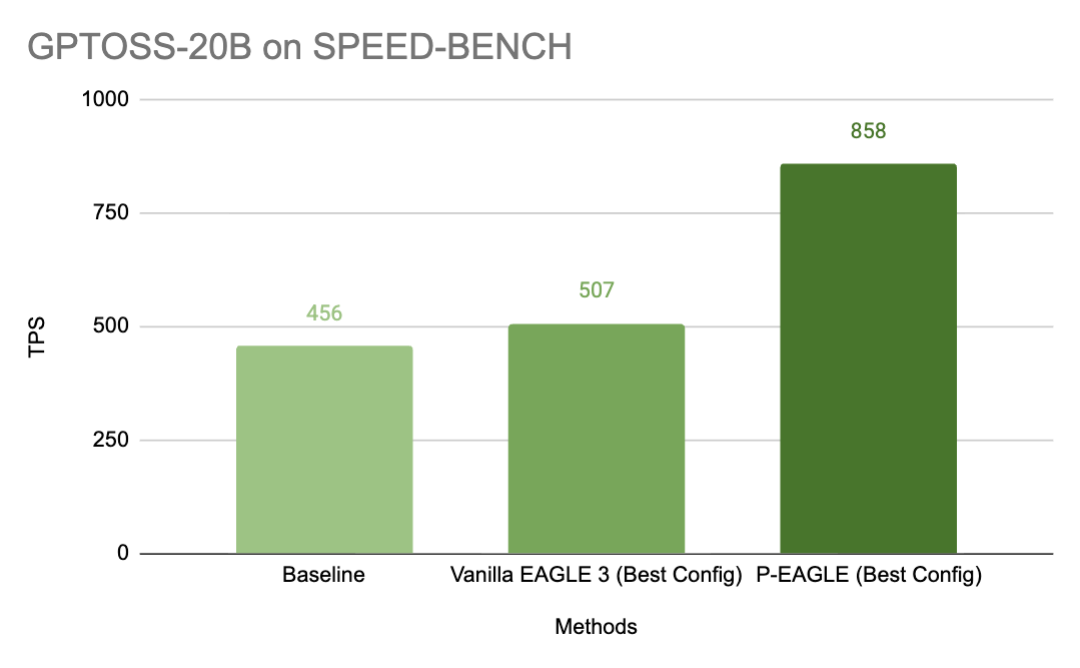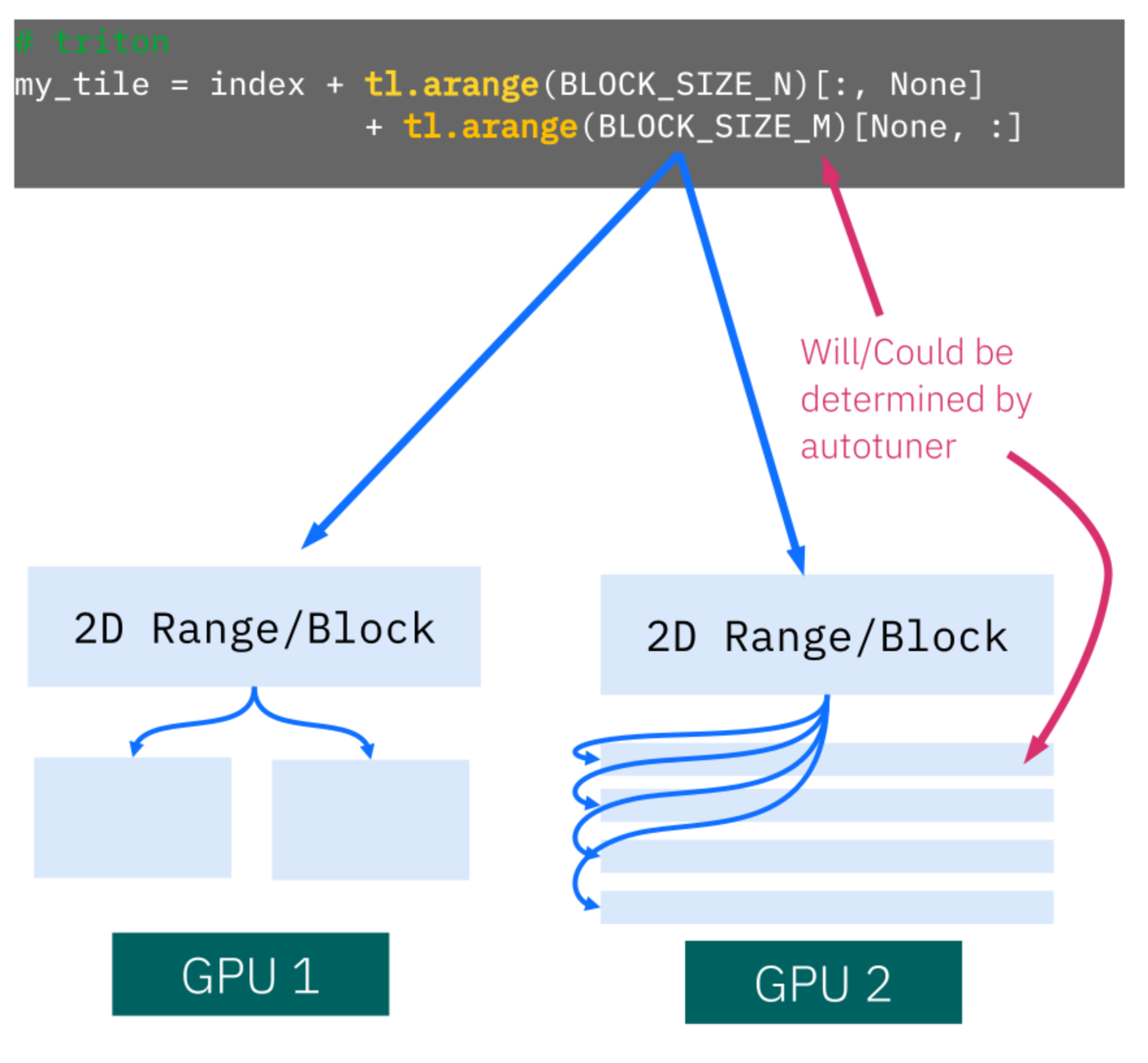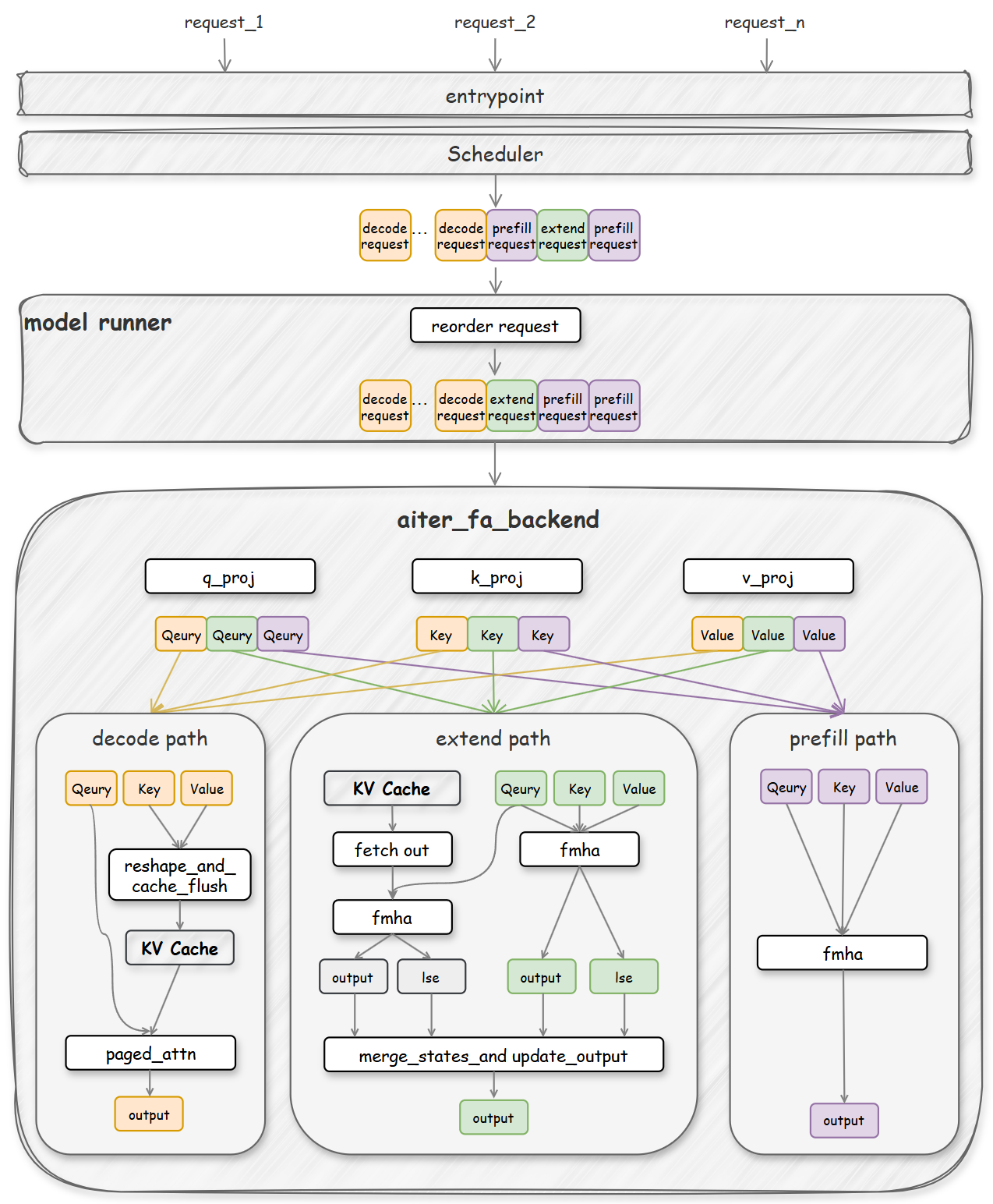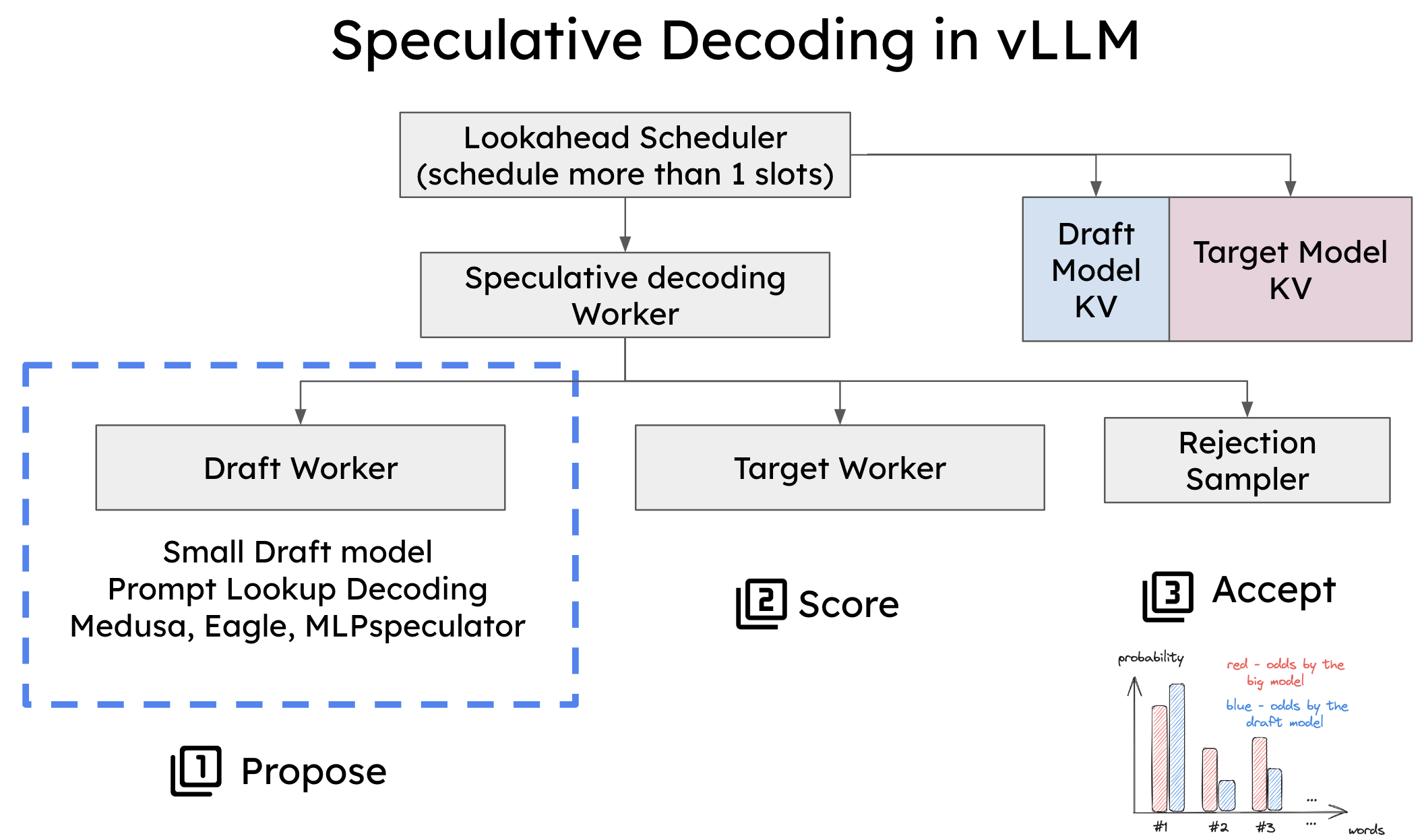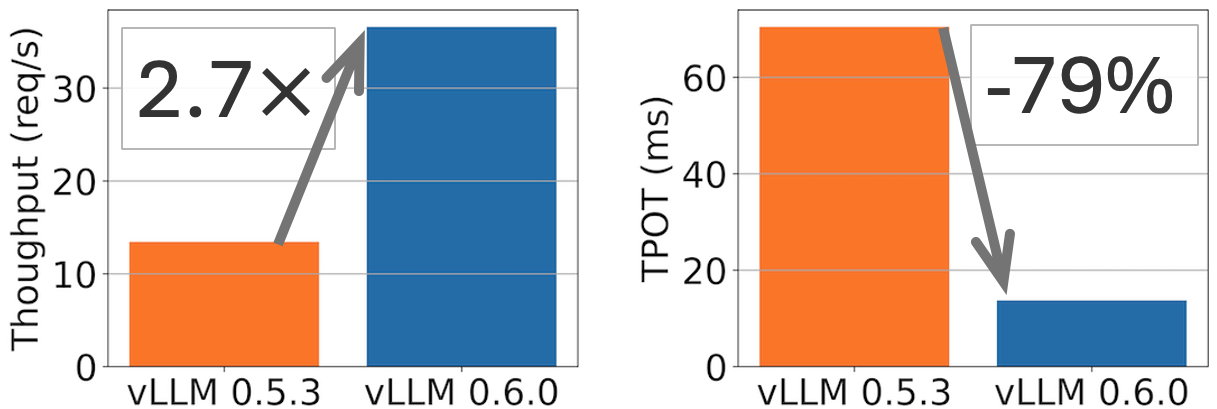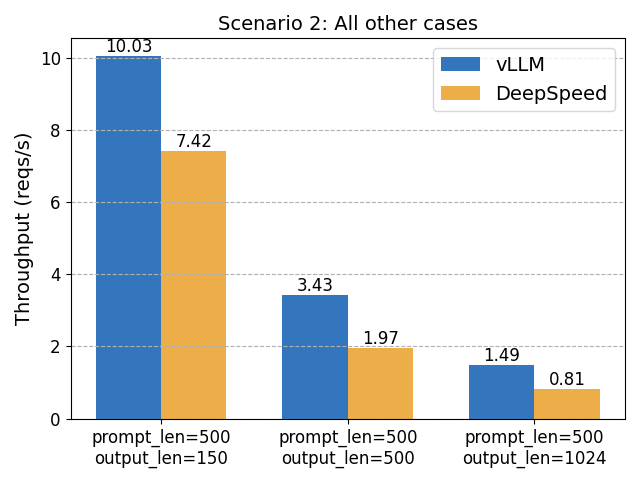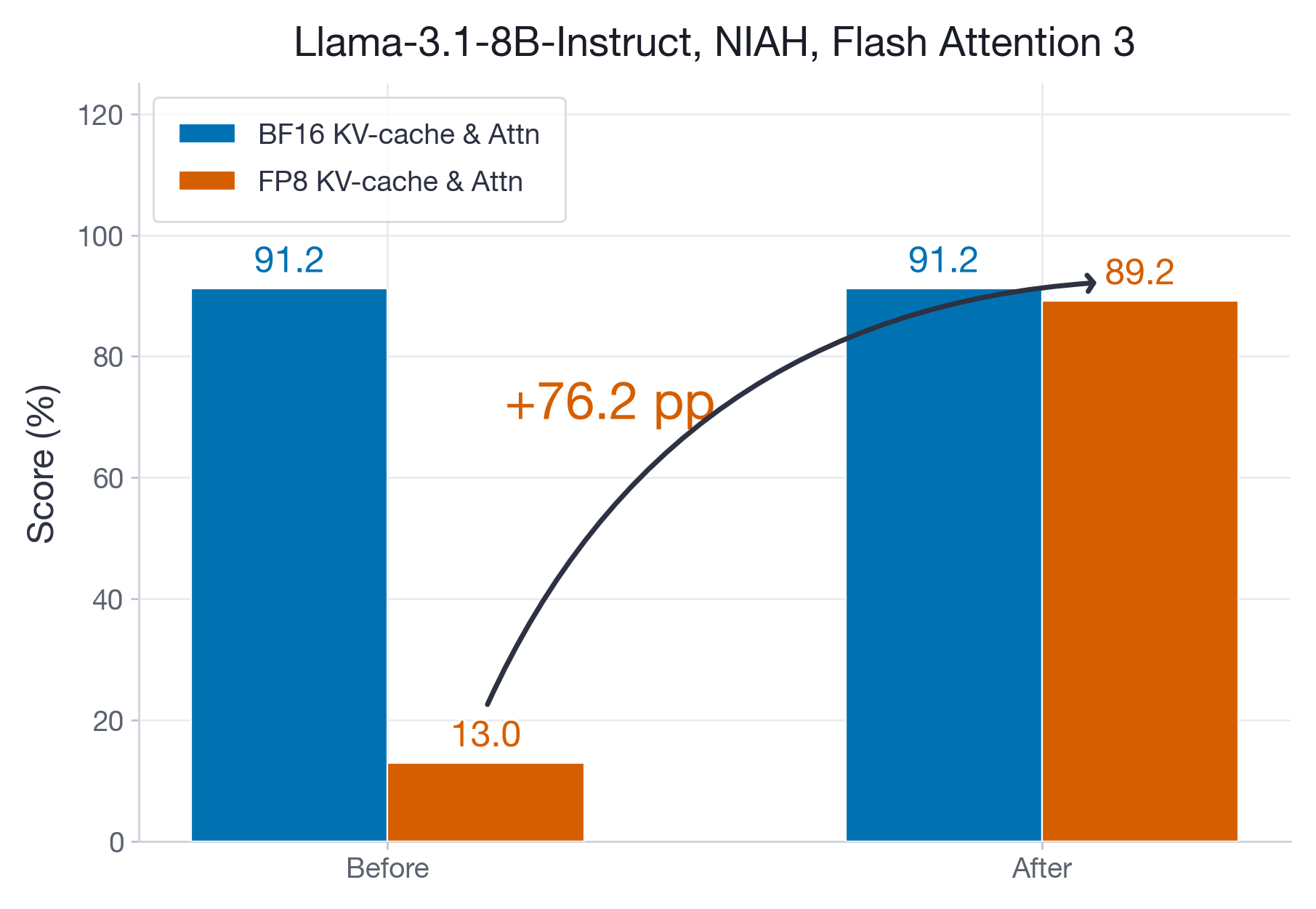
The State of FP8 KV-Cache and Attention Quantization in vLLM
·21 min read
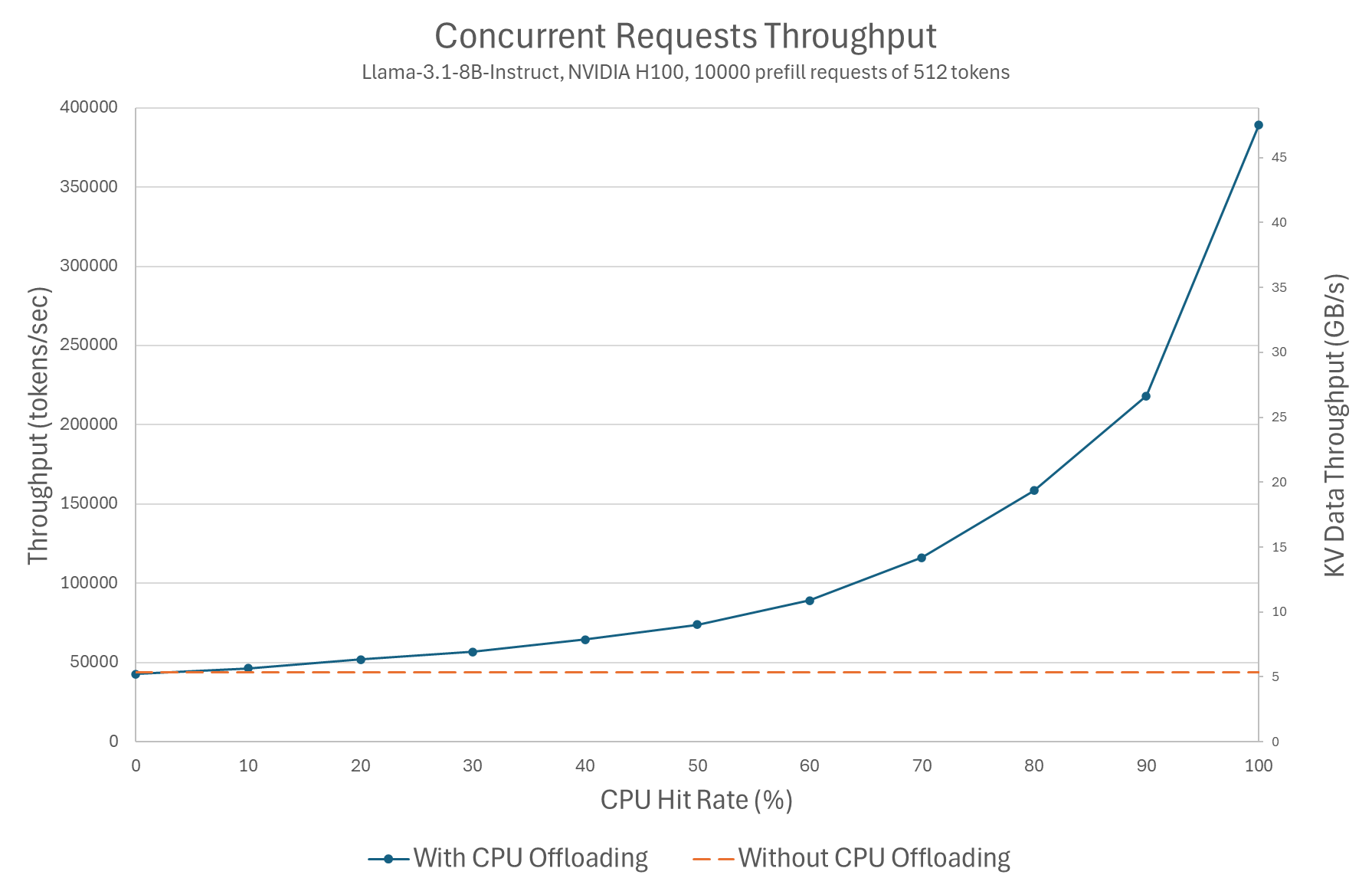
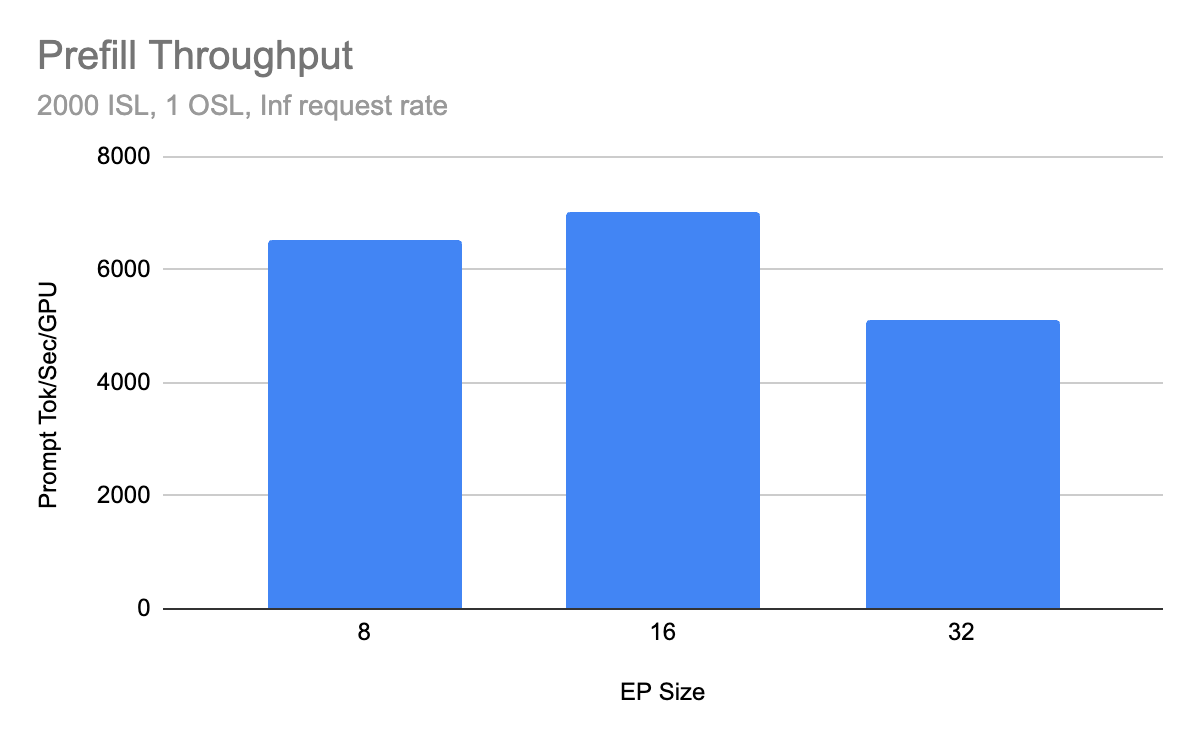
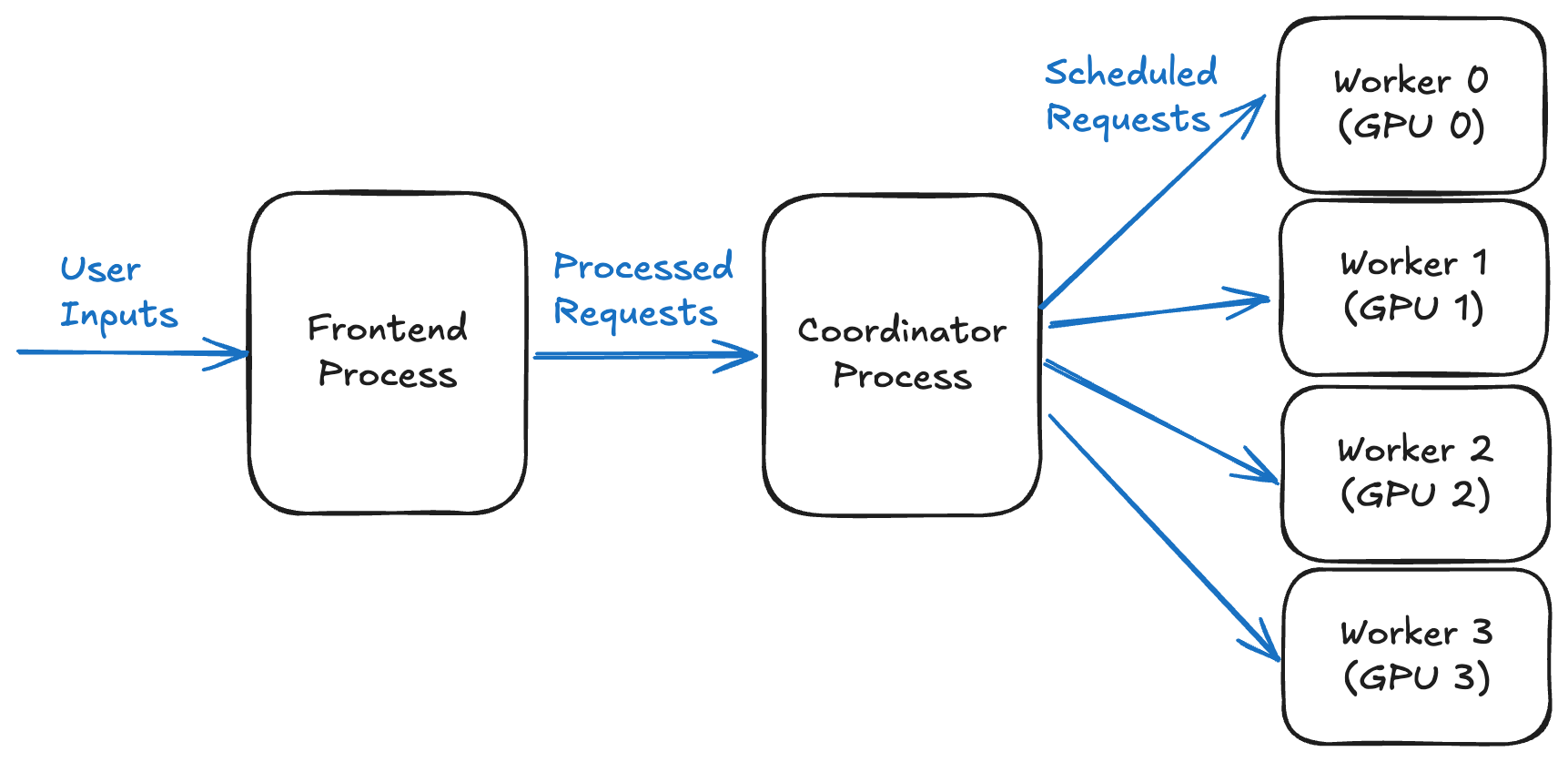
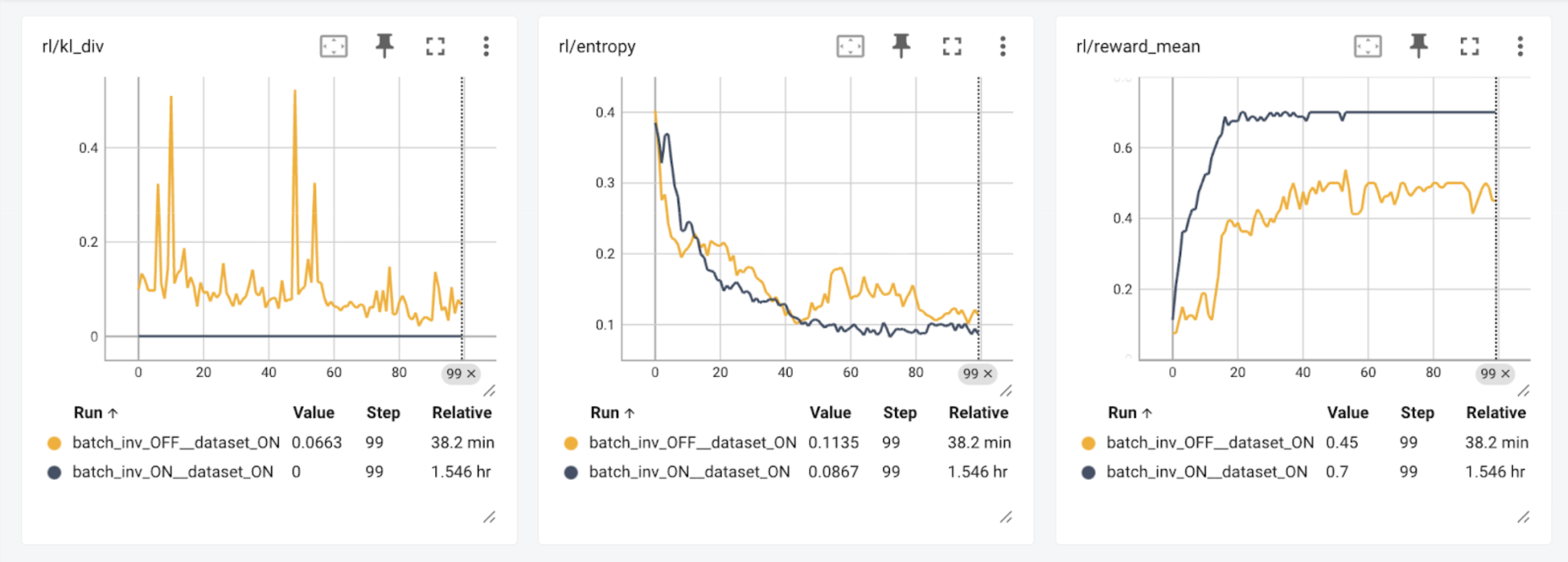
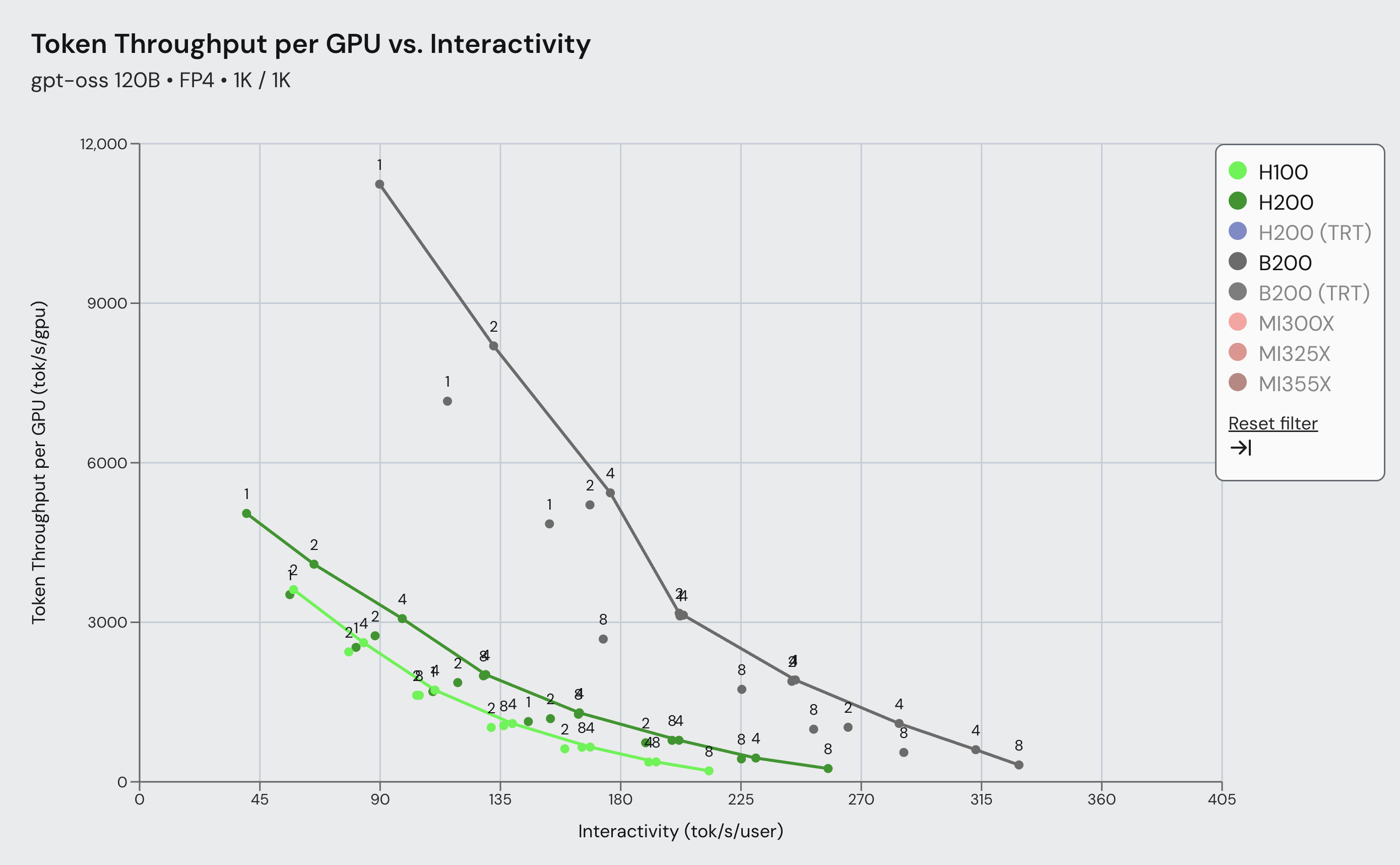
Long-context LLM serving is increasingly memory-bound: for standard full-attention decoders, the KV cache often dominates GPU memory at 128k+ contexts, and each decode step must read a large...